Updated readme
This commit is contained in:
parent
7e0b1a8647
commit
c8fc67d2b3
1 changed files with 63 additions and 63 deletions
126
README.md
126
README.md
|
|
@ -50,14 +50,14 @@ Kompute is provided as a single header file [`Kompute.hpp`](#setup). See [build-
|
|||
|
||||
### Your First Kompute (SIMPLE)
|
||||
|
||||
This simple example will show the basics of Kompute through the high level API, including:
|
||||
This simple example will show the basics of Kompute through the high level API.
|
||||
|
||||
1. Create and initialise a set of data tensors for processing
|
||||
2. Run compute shader synchronously
|
||||
3. Create managed sequence to submit batch operations to the CPU
|
||||
4. Map data back to host by running operation
|
||||
|
||||
View [more examples](https://kompute.cc/overview/advanced-examples.html#simple-examples).
|
||||
View the [extended version](#your-first-kompute-extended) or [more examples](https://kompute.cc/overview/advanced-examples.html#simple-examples).
|
||||
|
||||
```c++
|
||||
int main() {
|
||||
|
|
@ -85,7 +85,7 @@ int main() {
|
|||
|
||||
Your shader can be provided as raw glsl/hlsl string, SPIR-V bytes array (using our CLI), or string path to file containing either. Below are the examples of the valid ways of providing shader.
|
||||
|
||||
#### Raw GLSL/HLSL as std::string
|
||||
#### Passing raw GLSL/HLSL string
|
||||
|
||||
```c++
|
||||
static std::string shaderString = (R"(
|
||||
|
|
@ -105,15 +105,15 @@ static std::string shaderString = (R"(
|
|||
static std::vector<char> shader(shaderString.begin(), shaderString.end());
|
||||
```
|
||||
|
||||
#### SPIR-V Bytes as uint8_t / char array (using our CLI)
|
||||
#### Passing SPIR-V Bytes array
|
||||
|
||||
You can use the Kompute [shader-to-cpp-header CLI](https://kompute.cc/overview/shaders-to-headers.html) to convert your GLSL/HLSL or SPIRV shader into C++ header file (see documentation link for more info).
|
||||
You can use the Kompute [shader-to-cpp-header CLI](https://kompute.cc/overview/shaders-to-headers.html) to convert your GLSL/HLSL or SPIRV shader into C++ header file (see documentation link for more info). This is useful if you want your binary to be compiled with all relevant artifacts.
|
||||
|
||||
```c++
|
||||
static std::vector<char> shader = { 0x03, //... spirv bytes go here)
|
||||
```
|
||||
|
||||
#### File path to file containing raw glsl/hlsl or SPIRV bytes
|
||||
#### Path to file containing raw glsl/hlsl or SPIRV bytes
|
||||
|
||||
```c++
|
||||
static std::string shader = "path/to/shader.glsl";
|
||||
|
|
@ -121,9 +121,65 @@ static std::string shader = "path/to/shader.glsl";
|
|||
static std::string shader = "path/to/shader.glsl.spv";
|
||||
```
|
||||
|
||||
## Architectural Overview
|
||||
|
||||
The core architecture of Kompute include the following:
|
||||
* [Kompute Manager](https://kompute.cc/overview/reference.html#manager) - Base orchestrator which creates and manages device and child components
|
||||
* [Kompute Sequence](https://kompute.cc/overview/reference.html#sequence) - Container of operations that can be sent to GPU as batch
|
||||
* [Kompute Operation (Base)](https://kompute.cc/overview/reference.html#algorithm) - Base class from which all operations inherit
|
||||
* [Kompute Tensor](https://kompute.cc/overview/reference.html#tensor) - Tensor structured data used in GPU operations
|
||||
* [Kompute Algorithm](https://kompute.cc/overview/reference.html#algorithm) - Abstraction for (shader) code executed in the GPU
|
||||
|
||||
To see a full breakdown you can read further in the [C++ Class Reference](https://kompute.cc/overview/reference.html).
|
||||
|
||||
<table>
|
||||
<th>
|
||||
Full Vulkan Components
|
||||
</th>
|
||||
<th>
|
||||
Simplified Kompute Components
|
||||
</th>
|
||||
<tr>
|
||||
<td width=30%>
|
||||
|
||||
|
||||
<img width="100%" src="https://raw.githubusercontent.com/ethicalml/vulkan-kompute/master/docs/images/kompute-vulkan-architecture.jpg">
|
||||
|
||||
<br>
|
||||
<br>
|
||||
(very tiny, check the <a href="https://ethicalml.github.io/vulkan-kompute/overview/reference.html">full reference diagram in docs for details</a>)
|
||||
<br>
|
||||
<br>
|
||||
|
||||
<img width="100%" src="https://raw.githubusercontent.com/ethicalml/vulkan-kompute/master/docs/images/suspicious.jfif">
|
||||
|
||||
</td>
|
||||
<td>
|
||||
<img width="100%" src="https://raw.githubusercontent.com/ethicalml/vulkan-kompute/master/docs/images/kompute-architecture.jpg">
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
|
||||
## Asynchronous and Parallel Operations
|
||||
|
||||
Kompute provides flexibility to run operations in an asynrchonous way through Vulkan Fences. Furthermore, Kompute enables for explicit allocation of queues, which allow for parallel execution of operations across queue families.
|
||||
|
||||
The image below provides an intuition how Kompute Sequences can be allocated to different queues to enable parallel execution based on hardware. You can see the [hands on example](https://kompute.cc/overview/advanced-examples.html#parallel-operations), as well as the [detailed documentation page](https://kompute.cc/overview/async-parallel.html) describing how it would work using an NVIDIA 1650 as example.
|
||||
|
||||
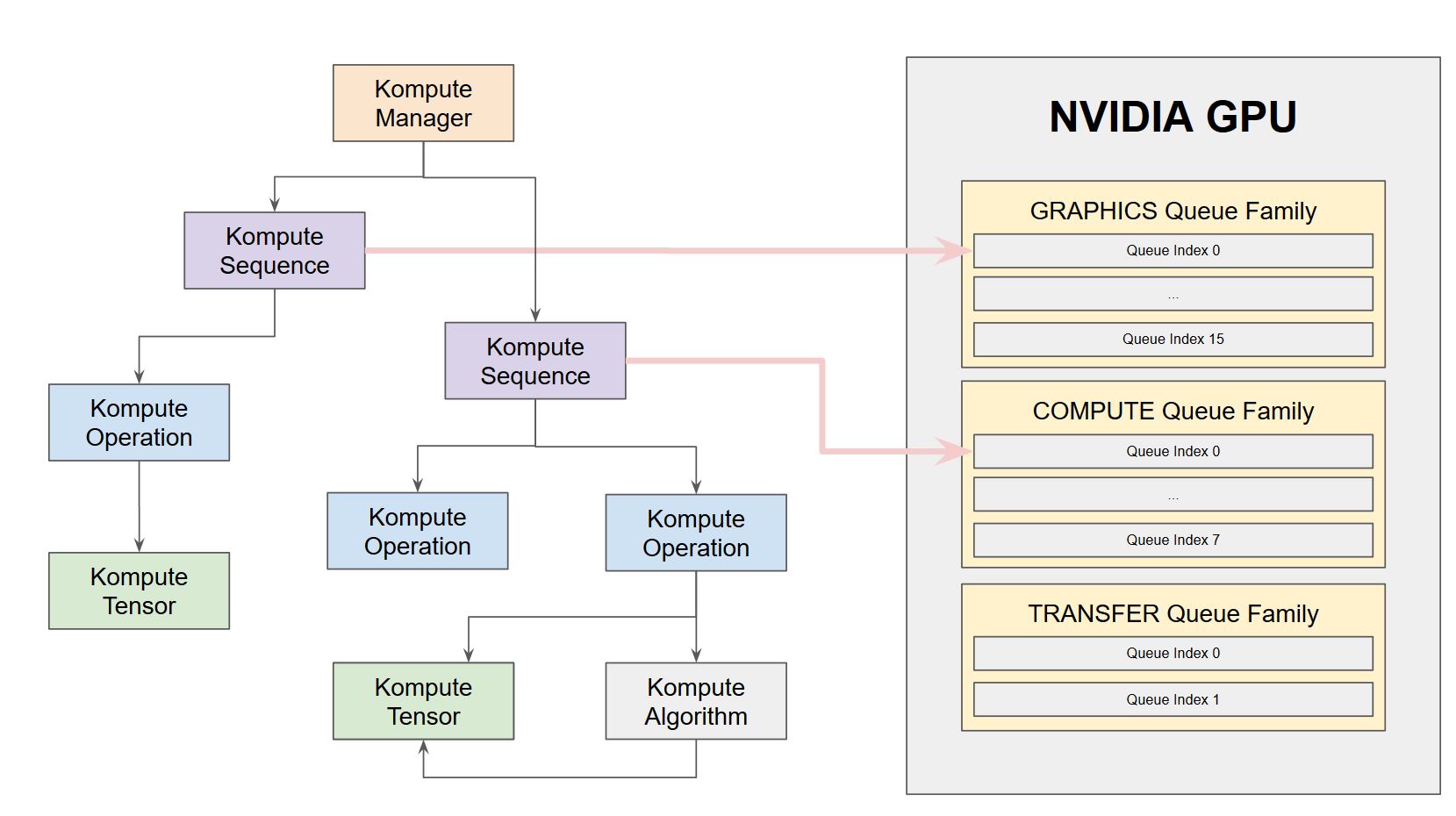
|
||||
|
||||
## Motivations
|
||||
|
||||
This project started after seeing that a lot of new and renowned ML & DL projects like Pytorch, Tensorflow, Alibaba DNN, between others, have either integrated or are looking to integrate the Vulkan SDK to add mobile (and cross-vendor) GPU support.
|
||||
|
||||
The Vulkan SDK offers a great low level interface that enables for highly specialized optimizations - however it comes at a cost of highly verbose code which requires 500-2000 lines of code to even begin writing application code. This has resulted in each of these projects having to implement the same baseline to abstract the non-compute related features of Vulkan. This large amount of non-standardised boiler-plate can result in limited knowledge transfer, higher chance of unique framework implementation bugs being introduced, between others.
|
||||
|
||||
We are currently developing Vulkan Kompute not to hide the Vulkan SDK interface (as it's incredibly well designed) but to augment it with a direct focus on Vulkan's GPU computing capabilities. [This article](https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a) provides a high level overview of the motivations of Kompute, together with a set of hands on examples that introduce both GPU computing as well as the core Vulkan Kompute architecture.
|
||||
|
||||
### Your First Kompute (EXTENDED)
|
||||
|
||||
We will cover the same example as above but leveraging more advanced Kompute features:
|
||||
We will now show the [same example as above](#your-first-kompute-simple) but leveraging more advanced Kompute features:
|
||||
|
||||
1. Create a set of data tensors in host memory for processing
|
||||
2. Map the tensor host data into GPU memory with Kompute Operation
|
||||
|
|
@ -194,62 +250,6 @@ int main() {
|
|||
* [Android NDK Mobile Kompute ML Application](https://towardsdatascience.com/gpu-accelerated-machine-learning-in-your-mobile-applications-using-the-android-ndk-vulkan-kompute-1e9da37b7617)
|
||||
* [Game Development Kompute ML in Godot Engine](https://towardsdatascience.com/supercharging-game-development-with-gpu-accelerated-ml-using-vulkan-kompute-the-godot-game-engine-4e75a84ea9f0)
|
||||
|
||||
## Architectural Overview
|
||||
|
||||
The core architecture of Kompute include the following:
|
||||
* [Kompute Manager](https://kompute.cc/overview/reference.html#manager) - Base orchestrator which creates and manages device and child components
|
||||
* [Kompute Sequence](https://kompute.cc/overview/reference.html#sequence) - Container of operations that can be sent to GPU as batch
|
||||
* [Kompute Operation (Base)](https://kompute.cc/overview/reference.html#algorithm) - Base class from which all operations inherit
|
||||
* [Kompute Tensor](https://kompute.cc/overview/reference.html#tensor) - Tensor structured data used in GPU operations
|
||||
* [Kompute Algorithm](https://kompute.cc/overview/reference.html#algorithm) - Abstraction for (shader) code executed in the GPU
|
||||
|
||||
To see a full breakdown you can read further in the [C++ Class Reference](https://kompute.cc/overview/reference.html).
|
||||
|
||||
<table>
|
||||
<th>
|
||||
Full Vulkan Components
|
||||
</th>
|
||||
<th>
|
||||
Simplified Kompute Components
|
||||
</th>
|
||||
<tr>
|
||||
<td width=30%>
|
||||
|
||||
|
||||
<img width="100%" src="https://raw.githubusercontent.com/ethicalml/vulkan-kompute/master/docs/images/kompute-vulkan-architecture.jpg">
|
||||
|
||||
<br>
|
||||
<br>
|
||||
(very tiny, check the <a href="https://ethicalml.github.io/vulkan-kompute/overview/reference.html">full reference diagram in docs for details</a>)
|
||||
<br>
|
||||
<br>
|
||||
|
||||
<img width="100%" src="https://raw.githubusercontent.com/ethicalml/vulkan-kompute/master/docs/images/suspicious.jfif">
|
||||
|
||||
</td>
|
||||
<td>
|
||||
<img width="100%" src="https://raw.githubusercontent.com/ethicalml/vulkan-kompute/master/docs/images/kompute-architecture.jpg">
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
|
||||
## Asynchronous and Parallel Operations
|
||||
|
||||
Kompute provides flexibility to run operations in an asynrchonous way through Vulkan Fences. Furthermore, Kompute enables for explicit allocation of queues, which allow for parallel execution of operations across queue families.
|
||||
|
||||
The image below provides an intuition how Kompute Sequences can be allocated to different queues to enable parallel execution based on hardware. You can see the [hands on example](https://kompute.cc/overview/advanced-examples.html#parallel-operations), as well as the [detailed documentation page](https://kompute.cc/overview/async-parallel.html) describing how it would work using an NVIDIA 1650 as example.
|
||||
|
||||

|
||||
|
||||
## Motivations
|
||||
|
||||
This project started after seeing that a lot of new and renowned ML & DL projects like Pytorch, Tensorflow, Alibaba DNN, between others, have either integrated or are looking to integrate the Vulkan SDK to add mobile (and cross-vendor) GPU support.
|
||||
|
||||
The Vulkan SDK offers a great low level interface that enables for highly specialized optimizations - however it comes at a cost of highly verbose code which requires 500-2000 lines of code to even begin writing application code. This has resulted in each of these projects having to implement the same baseline to abstract the non-compute related features of Vulkan. This large amount of non-standardised boiler-plate can result in limited knowledge transfer, higher chance of unique framework implementation bugs being introduced, between others.
|
||||
|
||||
We are currently developing Vulkan Kompute not to hide the Vulkan SDK interface (as it's incredibly well designed) but to augment it with a direct focus on Vulkan's GPU computing capabilities. [This article](https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a) provides a high level overview of the motivations of Kompute, together with a set of hands on examples that introduce both GPU computing as well as the core Vulkan Kompute architecture.
|
||||
|
||||
## Build Overview
|
||||
|
||||
The build system provided uses `cmake`, which allows for cross platform builds.
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue