Added documentation for parallel processing and refactored documentation
This commit is contained in:
parent
fba0a244a1
commit
35f82ed708
5 changed files with 695 additions and 420 deletions
305
README.md
305
README.md
|
|
@ -32,11 +32,10 @@
|
|||
|
||||
* [Single header](single_include/kompute/Kompute.hpp) library for simple import to your project
|
||||
* [Documentation](https://kompute.cc) leveraging doxygen and sphinx
|
||||
* BYOV: Bring-your-own-Vulkan design to play nice with existing Vulkan applications
|
||||
* Non-Vulkan core naming conventions to disambiguate Vulkan vs Kompute components
|
||||
* Asynchronous processing capabilities with granular mult-queue workload processing
|
||||
* Fast development cycles with shader tooling, but robust static shader binary bundles for prod
|
||||
* Explicit relationships for GPU and host memory ownership and memory management
|
||||
* [Asynchronous & parallel processing](#asynchronous-parallel-operations) capabilities with multi-queue command submission
|
||||
* [Non-Vulkan naming conventions](#components-architecture) to disambiguate Vulkan vs Kompute components
|
||||
* BYOV: [Bring-your-own-Vulkan design](#motivations) to play nice with existing Vulkan applications
|
||||
* Explicit relationships for GPU and host [memory ownership and memory management](https://kompute.cc/overview/memory-management.html)
|
||||
* End-to-end examples for [machine learning 🤖](https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a), [mobile development 📱](https://towardsdatascience.com/gpu-accelerated-machine-learning-in-your-mobile-applications-using-the-android-ndk-vulkan-kompute-1e9da37b7617), [game development 🎮](https://towardsdatascience.com/supercharging-game-development-with-gpu-accelerated-ml-using-vulkan-kompute-the-godot-game-engine-4e75a84ea9f0).
|
||||
|
||||

|
||||
|
|
@ -52,7 +51,7 @@ This project is built using cmake, providing a simple way to integrate as static
|
|||
|
||||
#### Your First Kompute
|
||||
|
||||
Pass compute shader data in glsl/hlsl text or compiled SPIR-V format (or as path to the file). View [more examples](#simple-examples).
|
||||
Pass compute shader data in glsl/hlsl text or compiled SPIR-V format (or as path to the file). View [more examples](https://kompute.cc/overview/advanced-examples.html#simple-examples).
|
||||
|
||||
```c++
|
||||
int main() {
|
||||
|
|
@ -98,279 +97,22 @@ int main() {
|
|||
}
|
||||
```
|
||||
|
||||
## Motivations
|
||||
|
||||
This project started after seeing that a lot of new and renowned ML & DL projects like Pytorch, Tensorflow, Alibaba DNN, between others, have either integrated or are looking to integrate the Vulkan GPU SDK to add mobile GPU (and cross-vendor GPU) support.
|
||||
|
||||
The Vulkan SDK offers a great low level interface that enables for highly specialized optimizations - however it comes at a cost of highly verbose code which requires 500-2000 lines of code to even begin writing application code. This has resulted in each of these projects having to implement the same baseline to abstract the non-compute related features of Vulkan, although it's not always the case, this can result in slower development cycles, and opportunities for bugs to be introduced.
|
||||
|
||||
We are currently developing Vulkan Kompute not to hide the Vulkan SDK interface (as it's incredibly well designed) but to augment it with a direct focus on Vulkan's GPU computing capabilities. [This article](https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a) provides a high level overview of the motivations of Kompute, together with a set of hands on examples that introduce both GPU computing as well as the core Vulkan Kompute architecture.
|
||||
|
||||
## More examples
|
||||
|
||||
### Simple examples
|
||||
|
||||
* [Pass shader as raw string](#your-first-kompute)
|
||||
* [Record batch commands with a Kompute Sequence](#record-batch-commands)
|
||||
* [Run Asynchronous Operations](#asynchronous-operations)
|
||||
* [Run Parallel Operations Across Multiple GPU Queues](#parallel-operations)
|
||||
* [Create your custom Kompute Operations](#your-custom-kompute-operation)
|
||||
* [Pass shader as raw string](https://kompute.cc/overview/advanced-examples.html#your-first-kompute)
|
||||
* [Record batch commands with a Kompute Sequence](https://kompute.cc/overview/advanced-examples.html#record-batch-commands)
|
||||
* [Run Asynchronous Operations](https://kompute.cc/overview/advanced-examples.html#asynchronous-operations)
|
||||
* [Run Parallel Operations Across Multiple GPU Queues](https://kompute.cc/overview/advanced-examples.html#parallel-operations)
|
||||
* [Create your custom Kompute Operations](https://kompute.cc/overview/advanced-examples.html#your-custom-kompute-operation)
|
||||
* [Implementing logistic regression from scratch](https://kompute.cc/overview/advanced-examples.html)
|
||||
|
||||
### End-to-end examples
|
||||
|
||||
* [Machine Learning Logistic Regression Implementation](https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a)
|
||||
* [Android NDK Mobile Kompute ML Application](https://towardsdatascience.com/gpu-accelerated-machine-learning-in-your-mobile-applications-using-the-android-ndk-vulkan-kompute-1e9da37b7617)
|
||||
* [Game Development Kompute ML in Godot Engine](https://towardsdatascience.com/supercharging-game-development-with-gpu-accelerated-ml-using-vulkan-kompute-the-godot-game-engine-4e75a84ea9f0)
|
||||
|
||||
#### Record batch commands
|
||||
|
||||
Record commands in a single submit by using a Sequence to send in batch to GPU. Back to [more examples](#simple-examples)
|
||||
|
||||
```c++
|
||||
int main() {
|
||||
|
||||
kp::Manager mgr;
|
||||
|
||||
std::shared_ptr<kp::Tensor> tensorLHS{ new kp::Tensor({ 1., 1., 1. }) };
|
||||
std::shared_ptr<kp::Tensor> tensorRHS{ new kp::Tensor({ 2., 2., 2. }) };
|
||||
std::shared_ptr<kp::Tensor> tensorOutput{ new kp::Tensor({ 0., 0., 0. }) };
|
||||
|
||||
// Create all the tensors in memory
|
||||
mgr.evalOpDefault<kp::OpCreateTensor>({tensorLHS, tensorRHS, tensorOutput});
|
||||
|
||||
// Create a new sequence
|
||||
std::weak_ptr<kp::Sequence> sqWeakPtr = mgr.getOrCreateManagedSequence();
|
||||
|
||||
if (std::shared_ptr<kp::Sequence> sq = sqWeakPtr.lock())
|
||||
{
|
||||
// Begin recording commands
|
||||
sq->begin();
|
||||
|
||||
// Record batch commands to send to GPU
|
||||
sq->record<kp::OpMult<>>({ tensorLHS, tensorRHS, tensorOutput });
|
||||
sq->record<kp::OpTensorCopy>({tensorOutput, tensorLHS, tensorRHS});
|
||||
|
||||
// Stop recording
|
||||
sq->end();
|
||||
|
||||
// Submit multiple batch operations to GPU
|
||||
size_t ITERATIONS = 5;
|
||||
for (size_t i = 0; i < ITERATIONS; i++) {
|
||||
sq->eval();
|
||||
}
|
||||
|
||||
// Sync GPU memory back to local tensor
|
||||
sq->begin();
|
||||
sq->record<kp::OpTensorSyncLocal>({tensorOutput});
|
||||
sq->end();
|
||||
sq->eval();
|
||||
}
|
||||
|
||||
// Print the output which iterates through OpMult 5 times
|
||||
// in this case the output is {32, 32 , 32}
|
||||
std::cout << fmt::format("Output: {}", tensorOutput.data()) << std::endl;
|
||||
}
|
||||
```
|
||||
|
||||
#### Asynchronous Operations
|
||||
|
||||
You can submit operations asynchronously with the async/await commands in the kp::Manager and kp::Sequence, which provides granularity on waiting on the vk::Fence. Back to [more examples](#simple-examples)
|
||||
|
||||
```c++
|
||||
int main() {
|
||||
|
||||
// You can allow Kompute to create the Vulkan components, or pass your existing ones
|
||||
kp::Manager mgr; // Selects device 0 unless explicitly requested
|
||||
|
||||
// Creates tensor an initializes GPU memory (below we show more granularity)
|
||||
auto tensor = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
|
||||
// Create tensors data explicitly in GPU with an operation
|
||||
mgr.evalOpAsyncDefault<kp::OpTensorCreate>({ tensor });
|
||||
|
||||
// Define your shader as a string (using string literals for simplicity)
|
||||
// (You can also pass the raw compiled bytes, or even path to file)
|
||||
std::string shader(R"(
|
||||
#version 450
|
||||
|
||||
layout (local_size_x = 1) in;
|
||||
|
||||
layout(set = 0, binding = 0) buffer b { float pb[]; };
|
||||
|
||||
shared uint sharedTotal[1];
|
||||
|
||||
void main() {
|
||||
uint index = gl_GlobalInvocationID.x;
|
||||
|
||||
sharedTotal[0] = 0;
|
||||
|
||||
// Iterating to simulate longer process
|
||||
for (int i = 0; i < 100000000; i++)
|
||||
{
|
||||
atomicAdd(sharedTotal[0], 1);
|
||||
}
|
||||
|
||||
pb[index] = sharedTotal[0];
|
||||
}
|
||||
)");
|
||||
|
||||
// We can now await for the previous submitted command
|
||||
// The first parameter can be the amount of time to wait
|
||||
// The time provided is in nanoseconds
|
||||
mgr.evalOpAwaitDefault(10000);
|
||||
|
||||
// Run Async Kompute operation on the parameters provided
|
||||
mgr.evalOpAsyncDefault<kp::OpAlgoBase<>>(
|
||||
{ tensor },
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Here we can do other work
|
||||
|
||||
// When we're ready we can wait
|
||||
// The default wait time is UINT64_MAX
|
||||
mgr.evalOpAwaitDefault()
|
||||
|
||||
// Sync the GPU memory back to the local tensor
|
||||
// We can still run synchronous jobs in our created sequence
|
||||
mgr.evalOpDefault<kp::OpTensorSyncLocal>({ tensor });
|
||||
|
||||
// Prints the output: B: { 100000000, ... }
|
||||
std::cout << fmt::format("B: {}",
|
||||
tensor.data()) << std::endl;
|
||||
}
|
||||
```
|
||||
|
||||
#### Parallel Operations
|
||||
|
||||
Besides being able to submit asynchronous operations, you can also leverage the underlying GPU compute queues to process operations in parallel.
|
||||
|
||||
This will depend on your underlying graphics card, but for example in NVIDIA graphics cards the operations submitted across queues in one family are not parallelizable, but operations submitted across queueFamilies can be parallelizable.
|
||||
|
||||
Below we show how you can parallelize operations in an [NVIDIA 1650](http://vulkan.gpuinfo.org/displayreport.php?id=9700#queuefamilies), which has a `GRAPHICS+COMPUTE` family on `index 0`, and `COMPUTE` family on `index 2`.
|
||||
|
||||
Back to [more examples](#simple-examples)
|
||||
|
||||
```c++
|
||||
int main() {
|
||||
|
||||
// In this case we select device 0, and for queues, one queue from familyIndex 0
|
||||
// and one queue from familyIndex 2
|
||||
uint32_t deviceIndex(0);
|
||||
std::vector<uint32_t> familyIndeces = {0, 2};
|
||||
|
||||
// We create a manager with device index, and queues by queue family index
|
||||
kp::Manager mgr(deviceIndex, familyIndeces);
|
||||
|
||||
// We need to create explicit sequences with their respective queues
|
||||
// The second parameter is the index in the familyIndex array which is relative
|
||||
// to the vector we created the manager with.
|
||||
mgr.createManagedSequence("queueOne", 0);
|
||||
mgr.createManagedSequence("queueTwo", 1);
|
||||
|
||||
// Creates tensor an initializes GPU memory (below we show more granularity)
|
||||
auto tensorA = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
auto tensorB = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
|
||||
// We run the first step synchronously on the default sequence
|
||||
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorA, tensorB });
|
||||
|
||||
// Define your shader as a string (using string literals for simplicity)
|
||||
// (You can also pass the raw compiled bytes, or even path to file)
|
||||
std::string shader(R"(
|
||||
#version 450
|
||||
|
||||
layout (local_size_x = 1) in;
|
||||
|
||||
layout(set = 0, binding = 0) buffer b { float pb[]; };
|
||||
|
||||
shared uint sharedTotal[1];
|
||||
|
||||
void main() {
|
||||
uint index = gl_GlobalInvocationID.x;
|
||||
|
||||
sharedTotal[0] = 0;
|
||||
|
||||
// Iterating to simulate longer process
|
||||
for (int i = 0; i < 100000000; i++)
|
||||
{
|
||||
atomicAdd(sharedTotal[0], 1);
|
||||
}
|
||||
|
||||
pb[index] = sharedTotal[0];
|
||||
}
|
||||
)");
|
||||
|
||||
// Run the first parallel operation in the `queueOne` sequence
|
||||
mgr.evalOpAsync<kp::OpAlgoBase<>>(
|
||||
{ tensorA },
|
||||
"queueOne",
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Run the second parallel operation in the `queueTwo` sequence
|
||||
mgr.evalOpAsync<kp::OpAlgoBase<>>(
|
||||
{ tensorB },
|
||||
"queueTwo",
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Here we can do other work
|
||||
|
||||
// We can now wait for thw two parallel tasks to finish
|
||||
mgr.evalOpAwait("queueOne")
|
||||
mgr.evalOpAwait("queueTwo")
|
||||
|
||||
// Sync the GPU memory back to the local tensor
|
||||
mgr.evalOp<kp::OpTensorSyncLocal>({ tensorA, tensorB });
|
||||
|
||||
// Prints the output: A: 100000000 B: 100000000
|
||||
std::cout << fmt::format("A: {}, B: {}",
|
||||
tensorA.data()[0], tensorB.data()[0]) << std::endl;
|
||||
}
|
||||
```
|
||||
|
||||
### Your Custom Kompute Operation
|
||||
|
||||
Build your own pre-compiled operations for domain specific workflows. Back to [more examples](#simple-examples)
|
||||
|
||||
We also provide tools that allow you to [convert shaders into C++ headers](https://github.com/EthicalML/vulkan-kompute/blob/master/scripts/convert_shaders.py#L40).
|
||||
|
||||
```c++
|
||||
|
||||
template<uint32_t tX = 0, uint32_t tY = 0, uint32_t tZ = 0>
|
||||
class OpMyCustom : public OpAlgoBase<tX, tY, tZ>
|
||||
{
|
||||
public:
|
||||
OpMyCustom(std::shared_ptr<vk::PhysicalDevice> physicalDevice,
|
||||
std::shared_ptr<vk::Device> device,
|
||||
std::shared_ptr<vk::CommandBuffer> commandBuffer,
|
||||
std::vector<std::shared_ptr<Tensor>> tensors)
|
||||
: OpAlgoBase<tX, tY, tZ>(physicalDevice, device, commandBuffer, tensors, "")
|
||||
{
|
||||
// Perform your custom steps such as reading from a shader file
|
||||
this->mShaderFilePath = "shaders/glsl/opmult.comp";
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
int main() {
|
||||
|
||||
kp::Manager mgr; // Automatically selects Device 0
|
||||
|
||||
// Create 3 tensors of default type float
|
||||
auto tensorLhs = std::make_shared<kp::Tensor>(kp::Tensor({ 0., 1., 2. }));
|
||||
auto tensorRhs = std::make_shared<kp::Tensor>(kp::Tensor({ 2., 4., 6. }));
|
||||
auto tensorOut = std::make_shared<kp::Tensor>(kp::Tensor({ 0., 0., 0. }));
|
||||
|
||||
// Create tensors data explicitly in GPU with an operation
|
||||
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorLhs, tensorRhs, tensorOut });
|
||||
|
||||
// Run Kompute operation on the parameters provided with dispatch layout
|
||||
mgr.evalOpDefault<kp::OpMyCustom<3, 1, 1>>(
|
||||
{ tensorLhs, tensorRhs, tensorOut });
|
||||
|
||||
// Prints the output which is { 0, 4, 12 }
|
||||
std::cout << fmt::format("Output: {}", tensorOutput.data()) << std::endl;
|
||||
}
|
||||
```
|
||||
* `Machine Learning Logistic Regression Implementation <https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a>`_
|
||||
* `Android NDK Mobile Kompute ML Application <https://towardsdatascience.com/gpu-accelerated-machine-learning-in-your-mobile-applications-using-the-android-ndk-vulkan-kompute-1e9da37b7617>`_
|
||||
* `Game Development Kompute ML in Godot Engine <https://towardsdatascience.com/supercharging-game-development-with-gpu-accelerated-ml-using-vulkan-kompute-the-godot-game-engine-4e75a84ea9f0>`_
|
||||
|
||||
## Components & Architecture
|
||||
|
||||
|
|
@ -412,6 +154,25 @@ Simplified Kompute Components
|
|||
</tr>
|
||||
</table>
|
||||
|
||||
|
||||
## Asynchronous and Parallel Operations
|
||||
|
||||
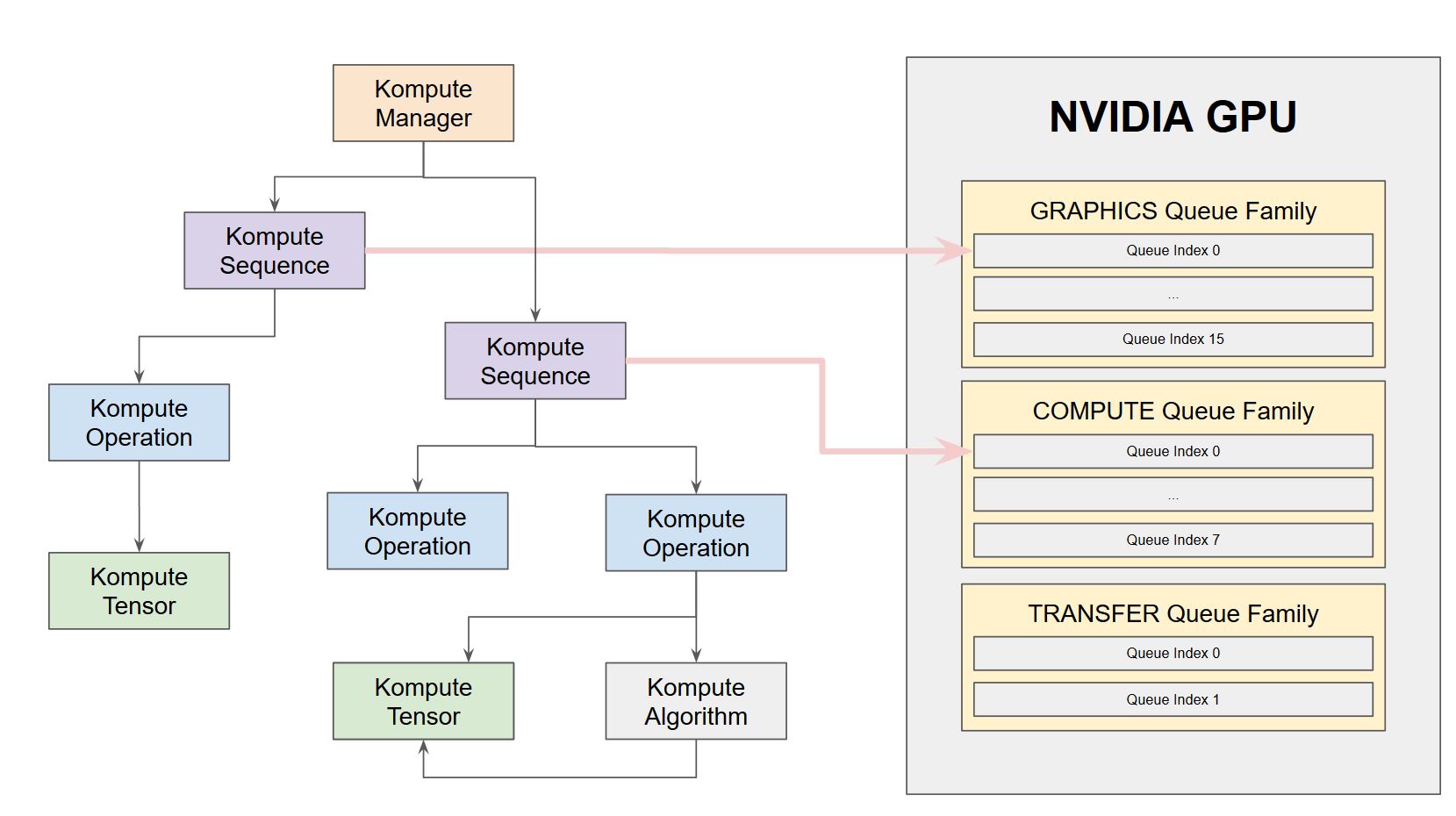
Kompute provides flexibility to run operations in an asynrchonous way through Vulkan Fences. Furthermore, Kompute enables for explicit allocation of queues, which allow for parallel execution of operations across queue families.
|
||||
|
||||
The image below provides an intuition how Kompute Sequences can be allocated to different queues for to enable parallel execution based on hardware. This allows for workloads to be run in parallel across the graphics and compute queue families.
|
||||
|
||||
You can see the [hands on example](https://kompute.cc/overview/advanced-examples.html#parallel-operations), as well as the [detailed documentation page](https://kompute.cc/overview/async-parallel.html) describing how it would work using an NVIDIA 1650 as example.
|
||||
|
||||
|
||||
|
||||
## Motivations
|
||||
|
||||
This project started after seeing that a lot of new and renowned ML & DL projects like Pytorch, Tensorflow, Alibaba DNN, between others, have either integrated or are looking to integrate the Vulkan GPU SDK to add mobile GPU (and cross-vendor GPU) support.
|
||||
|
||||
The Vulkan SDK offers a great low level interface that enables for highly specialized optimizations - however it comes at a cost of highly verbose code which requires 500-2000 lines of code to even begin writing application code. This has resulted in each of these projects having to implement the same baseline to abstract the non-compute related features of Vulkan, although it's not always the case, this can result in slower development cycles, and opportunities for bugs to be introduced.
|
||||
|
||||
We are currently developing Vulkan Kompute not to hide the Vulkan SDK interface (as it's incredibly well designed) but to augment it with a direct focus on Vulkan's GPU computing capabilities. [This article](https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a) provides a high level overview of the motivations of Kompute, together with a set of hands on examples that introduce both GPU computing as well as the core Vulkan Kompute architecture.
|
||||
|
||||
## Build Overview
|
||||
|
||||
The build system provided is `cmake` which allows for cross platform builds. Below is a brief overview of the build system.
|
||||
|
|
|
|||
BIN
docs/images/queue-allocation.jpg
Executable file
BIN
docs/images/queue-allocation.jpg
Executable file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 137 KiB |
|
|
@ -11,12 +11,12 @@ Index
|
|||
:maxdepth: 2
|
||||
:titlesonly:
|
||||
|
||||
Class Documentation and C++ Reference <overview/reference>
|
||||
Advanced Examples <overview/advanced-examples>
|
||||
Asynchronous & Parallel Operations <overview/async-parallel>
|
||||
Memory Management Principles <overview/memory-management>
|
||||
Converting GLSL/HLSL Shaders to C++ Headers <overview/shaders-to-headers>
|
||||
Mobile App Intergration (Android) <overview/mobile-android>
|
||||
Game Engine Integration (Godot Engine) <overview/game-engine-godot>
|
||||
Converting GLSL/HLSL Shaders to C++ Headers <overview/shaders-to-headers>
|
||||
Asynchronous & Parallel Operations <overview/async-parallel>
|
||||
Class Documentation and C++ Reference <overview/reference>
|
||||
Memory Management Principles <overview/memory-management>
|
||||
Code Index <genindex>
|
||||
|
||||
|
|
|
|||
|
|
@ -1,100 +1,426 @@
|
|||
.. role:: raw-html-m2r(raw)
|
||||
:format: html
|
||||
|
||||
Advanced Examples
|
||||
==================
|
||||
|
||||
Examples
|
||||
========
|
||||
|
||||
The power of Kompute comes in when the interface is used for complex computations. This section contains an outline of the advanced / end-to-end examples available.
|
||||
|
||||
Currently the advanced examples available include:
|
||||
Simple examples
|
||||
^^^^^^^^^^^^^^^
|
||||
|
||||
* `Machine Learning Logistic Regression Implementation <https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a`_
|
||||
* `Android NDK Mobile Kompute ML Application <https://towardsdatascience.com/gpu-accelerated-machine-learning-in-your-mobile-applications-using-the-android-ndk-vulkan-kompute-1e9da37b7617`_
|
||||
* `Game Development Kompute ML in Godot Engine <https://towardsdatascience.com/supercharging-game-development-with-gpu-accelerated-ml-using-vulkan-kompute-the-godot-game-engine-4e75a84ea9f0`_
|
||||
|
||||
Below there is also a simple implementation of the logistic regression algorithm using Vulkan Kompute.
|
||||
* `Pass shader as raw string <#simple-shader-example>`_
|
||||
* `Record batch commands with a Kompute Sequence <#record-batch-commands>`_
|
||||
* `Run Asynchronous Operations <#asynchronous-operations>`_
|
||||
* `Run Parallel Operations Across Multiple GPU Queues <#parallel-operations>`_
|
||||
* `Create your custom Kompute Operations <#your-custom-kompute-operation>`_
|
||||
* `Implementing logistic regression from scratch <#logistic-regression-example>`_
|
||||
|
||||
End-to-end examples
|
||||
^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
|
||||
* `Machine Learning Logistic Regression Implementation <https://towardsdatascience.com/machine-learning-and-data-processing-in-the-gpu-with-vulkan-kompute-c9350e5e5d3a>`_
|
||||
* `Android NDK Mobile Kompute ML Application <https://towardsdatascience.com/gpu-accelerated-machine-learning-in-your-mobile-applications-using-the-android-ndk-vulkan-kompute-1e9da37b7617>`_
|
||||
* `Game Development Kompute ML in Godot Engine <https://towardsdatascience.com/supercharging-game-development-with-gpu-accelerated-ml-using-vulkan-kompute-the-godot-game-engine-4e75a84ea9f0>`_
|
||||
|
||||
|
||||
Simple Shader Example
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Pass compute shader data in glsl/hlsl text or compiled SPIR-V format (or as path to the file). Back to `examples list <#simple-examples>`_.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
int main() {
|
||||
|
||||
// You can allow Kompute to create the Vulkan components, or pass your existing ones
|
||||
kp::Manager mgr; // Selects device 0 unless explicitly requested
|
||||
|
||||
// Creates tensor an initializes GPU memory (below we show more granularity)
|
||||
auto tensorA = std::make_shared<kp::Tensor>(kp::Tensor({ 3., 4., 5. }));
|
||||
auto tensorB = std::make_shared<kp::Tensor>(kp::Tensor({ 0., 0., 0. }));
|
||||
|
||||
// Create tensors data explicitly in GPU with an operation
|
||||
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorA, tensorB });
|
||||
|
||||
// Define your shader as a string (using string literals for simplicity)
|
||||
// (You can also pass the raw compiled bytes, or even path to file)
|
||||
std::string shader(R"(
|
||||
#version 450
|
||||
|
||||
layout (local_size_x = 1) in;
|
||||
|
||||
layout(set = 0, binding = 0) buffer a { float pa[]; };
|
||||
layout(set = 0, binding = 1) buffer b { float pb[]; };
|
||||
|
||||
void main() {
|
||||
uint index = gl_GlobalInvocationID.x;
|
||||
pb[index] = pa[index];
|
||||
pa[index] = index;
|
||||
}
|
||||
)");
|
||||
|
||||
// Run Kompute operation on the parameters provided with dispatch layout
|
||||
mgr.evalOpDefault<kp::OpAlgoBase<3, 1, 1>>(
|
||||
{ tensorA, tensorB },
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Sync the GPU memory back to the local tensor
|
||||
mgr.evalOpDefault<kp::OpTensorSyncLocal>({ tensorA, tensorB });
|
||||
|
||||
// Prints the output which is A: { 0, 1, 2 } B: { 3, 4, 5 }
|
||||
std::cout << fmt::format("A: {}, B: {}",
|
||||
tensorA.data(), tensorB.data()) << std::endl;
|
||||
}
|
||||
|
||||
Record batch commands
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Record commands in a single submit by using a Sequence to send in batch to GPU. Back to `examples list <#simple-examples>`_
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
int main() {
|
||||
|
||||
kp::Manager mgr;
|
||||
|
||||
std::shared_ptr<kp::Tensor> tensorLHS{ new kp::Tensor({ 1., 1., 1. }) };
|
||||
std::shared_ptr<kp::Tensor> tensorRHS{ new kp::Tensor({ 2., 2., 2. }) };
|
||||
std::shared_ptr<kp::Tensor> tensorOutput{ new kp::Tensor({ 0., 0., 0. }) };
|
||||
|
||||
// Create all the tensors in memory
|
||||
mgr.evalOpDefault<kp::OpCreateTensor>({tensorLHS, tensorRHS, tensorOutput});
|
||||
|
||||
// Create a new sequence
|
||||
std::weak_ptr<kp::Sequence> sqWeakPtr = mgr.getOrCreateManagedSequence();
|
||||
|
||||
if (std::shared_ptr<kp::Sequence> sq = sqWeakPtr.lock())
|
||||
{
|
||||
// Begin recording commands
|
||||
sq->begin();
|
||||
|
||||
// Record batch commands to send to GPU
|
||||
sq->record<kp::OpMult<>>({ tensorLHS, tensorRHS, tensorOutput });
|
||||
sq->record<kp::OpTensorCopy>({tensorOutput, tensorLHS, tensorRHS});
|
||||
|
||||
// Stop recording
|
||||
sq->end();
|
||||
|
||||
// Submit multiple batch operations to GPU
|
||||
size_t ITERATIONS = 5;
|
||||
for (size_t i = 0; i < ITERATIONS; i++) {
|
||||
sq->eval();
|
||||
}
|
||||
|
||||
// Sync GPU memory back to local tensor
|
||||
sq->begin();
|
||||
sq->record<kp::OpTensorSyncLocal>({tensorOutput});
|
||||
sq->end();
|
||||
sq->eval();
|
||||
}
|
||||
|
||||
// Print the output which iterates through OpMult 5 times
|
||||
// in this case the output is {32, 32 , 32}
|
||||
std::cout << fmt::format("Output: {}", tensorOutput.data()) << std::endl;
|
||||
}
|
||||
|
||||
Asynchronous Operations
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
You can submit operations asynchronously with the async/await commands in the kp::Manager and kp::Sequence, which provides granularity on waiting on the vk::Fence. Back to `examples list <#simple-examples>`_
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
int main() {
|
||||
|
||||
// You can allow Kompute to create the Vulkan components, or pass your existing ones
|
||||
kp::Manager mgr; // Selects device 0 unless explicitly requested
|
||||
|
||||
// Creates tensor an initializes GPU memory (below we show more granularity)
|
||||
auto tensor = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
|
||||
// Create tensors data explicitly in GPU with an operation
|
||||
mgr.evalOpAsyncDefault<kp::OpTensorCreate>({ tensor });
|
||||
|
||||
// Define your shader as a string (using string literals for simplicity)
|
||||
// (You can also pass the raw compiled bytes, or even path to file)
|
||||
std::string shader(R"(
|
||||
#version 450
|
||||
|
||||
layout (local_size_x = 1) in;
|
||||
|
||||
layout(set = 0, binding = 0) buffer b { float pb[]; };
|
||||
|
||||
shared uint sharedTotal[1];
|
||||
|
||||
void main() {
|
||||
uint index = gl_GlobalInvocationID.x;
|
||||
|
||||
sharedTotal[0] = 0;
|
||||
|
||||
// Iterating to simulate longer process
|
||||
for (int i = 0; i < 100000000; i++)
|
||||
{
|
||||
atomicAdd(sharedTotal[0], 1);
|
||||
}
|
||||
|
||||
pb[index] = sharedTotal[0];
|
||||
}
|
||||
)");
|
||||
|
||||
// We can now await for the previous submitted command
|
||||
// The first parameter can be the amount of time to wait
|
||||
// The time provided is in nanoseconds
|
||||
mgr.evalOpAwaitDefault(10000);
|
||||
|
||||
// Run Async Kompute operation on the parameters provided
|
||||
mgr.evalOpAsyncDefault<kp::OpAlgoBase<>>(
|
||||
{ tensor },
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Here we can do other work
|
||||
|
||||
// When we're ready we can wait
|
||||
// The default wait time is UINT64_MAX
|
||||
mgr.evalOpAwaitDefault()
|
||||
|
||||
// Sync the GPU memory back to the local tensor
|
||||
// We can still run synchronous jobs in our created sequence
|
||||
mgr.evalOpDefault<kp::OpTensorSyncLocal>({ tensor });
|
||||
|
||||
// Prints the output: B: { 100000000, ... }
|
||||
std::cout << fmt::format("B: {}",
|
||||
tensor.data()) << std::endl;
|
||||
}
|
||||
|
||||
Parallel Operations
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Besides being able to submit asynchronous operations, you can also leverage the underlying GPU compute queues to process operations in parallel.
|
||||
|
||||
This will depend on your underlying graphics card, but for example in NVIDIA graphics cards the operations submitted across queues in one family are not parallelizable, but operations submitted across queueFamilies can be parallelizable.
|
||||
|
||||
Below we show how you can parallelize operations in an `NVIDIA 1650 <http://vulkan.gpuinfo.org/displayreport.php?id=9700#queuefamilies>`_\ , which has a ``GRAPHICS+COMPUTE`` family on ``index 0``\ , and ``COMPUTE`` family on ``index 2``.
|
||||
|
||||
Back to `examples list <#simple-examples>`_.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
int main() {
|
||||
|
||||
// In this case we select device 0, and for queues, one queue from familyIndex 0
|
||||
// and one queue from familyIndex 2
|
||||
uint32_t deviceIndex(0);
|
||||
std::vector<uint32_t> familyIndeces = {0, 2};
|
||||
|
||||
// We create a manager with device index, and queues by queue family index
|
||||
kp::Manager mgr(deviceIndex, familyIndeces);
|
||||
|
||||
// We need to create explicit sequences with their respective queues
|
||||
// The second parameter is the index in the familyIndex array which is relative
|
||||
// to the vector we created the manager with.
|
||||
mgr.createManagedSequence("queueOne", 0);
|
||||
mgr.createManagedSequence("queueTwo", 1);
|
||||
|
||||
// Creates tensor an initializes GPU memory (below we show more granularity)
|
||||
auto tensorA = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
auto tensorB = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
|
||||
// We run the first step synchronously on the default sequence
|
||||
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorA, tensorB });
|
||||
|
||||
// Define your shader as a string (using string literals for simplicity)
|
||||
// (You can also pass the raw compiled bytes, or even path to file)
|
||||
std::string shader(R"(
|
||||
#version 450
|
||||
|
||||
layout (local_size_x = 1) in;
|
||||
|
||||
layout(set = 0, binding = 0) buffer b { float pb[]; };
|
||||
|
||||
shared uint sharedTotal[1];
|
||||
|
||||
void main() {
|
||||
uint index = gl_GlobalInvocationID.x;
|
||||
|
||||
sharedTotal[0] = 0;
|
||||
|
||||
// Iterating to simulate longer process
|
||||
for (int i = 0; i < 100000000; i++)
|
||||
{
|
||||
atomicAdd(sharedTotal[0], 1);
|
||||
}
|
||||
|
||||
pb[index] = sharedTotal[0];
|
||||
}
|
||||
)");
|
||||
|
||||
// Run the first parallel operation in the `queueOne` sequence
|
||||
mgr.evalOpAsync<kp::OpAlgoBase<>>(
|
||||
{ tensorA },
|
||||
"queueOne",
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Run the second parallel operation in the `queueTwo` sequence
|
||||
mgr.evalOpAsync<kp::OpAlgoBase<>>(
|
||||
{ tensorB },
|
||||
"queueTwo",
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Here we can do other work
|
||||
|
||||
// We can now wait for thw two parallel tasks to finish
|
||||
mgr.evalOpAwait("queueOne")
|
||||
mgr.evalOpAwait("queueTwo")
|
||||
|
||||
// Sync the GPU memory back to the local tensor
|
||||
mgr.evalOp<kp::OpTensorSyncLocal>({ tensorA, tensorB });
|
||||
|
||||
// Prints the output: A: 100000000 B: 100000000
|
||||
std::cout << fmt::format("A: {}, B: {}",
|
||||
tensorA.data()[0], tensorB.data()[0]) << std::endl;
|
||||
}
|
||||
|
||||
Your Custom Kompute Operation
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Build your own pre-compiled operations for domain specific workflows. Back to `examples list <#simple-examples>`_
|
||||
|
||||
We also provide tools that allow you to `convert shaders into C++ headers <https://github.com/EthicalML/vulkan-kompute/blob/master/scripts/convert_shaders.py#L40>`_.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
template<uint32_t tX = 0, uint32_t tY = 0, uint32_t tZ = 0>
|
||||
class OpMyCustom : public OpAlgoBase<tX, tY, tZ>
|
||||
{
|
||||
public:
|
||||
OpMyCustom(std::shared_ptr<vk::PhysicalDevice> physicalDevice,
|
||||
std::shared_ptr<vk::Device> device,
|
||||
std::shared_ptr<vk::CommandBuffer> commandBuffer,
|
||||
std::vector<std::shared_ptr<Tensor>> tensors)
|
||||
: OpAlgoBase<tX, tY, tZ>(physicalDevice, device, commandBuffer, tensors, "")
|
||||
{
|
||||
// Perform your custom steps such as reading from a shader file
|
||||
this->mShaderFilePath = "shaders/glsl/opmult.comp";
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
int main() {
|
||||
|
||||
kp::Manager mgr; // Automatically selects Device 0
|
||||
|
||||
// Create 3 tensors of default type float
|
||||
auto tensorLhs = std::make_shared<kp::Tensor>(kp::Tensor({ 0., 1., 2. }));
|
||||
auto tensorRhs = std::make_shared<kp::Tensor>(kp::Tensor({ 2., 4., 6. }));
|
||||
auto tensorOut = std::make_shared<kp::Tensor>(kp::Tensor({ 0., 0., 0. }));
|
||||
|
||||
// Create tensors data explicitly in GPU with an operation
|
||||
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorLhs, tensorRhs, tensorOut });
|
||||
|
||||
// Run Kompute operation on the parameters provided with dispatch layout
|
||||
mgr.evalOpDefault<kp::OpMyCustom<3, 1, 1>>(
|
||||
{ tensorLhs, tensorRhs, tensorOut });
|
||||
|
||||
// Prints the output which is { 0, 4, 12 }
|
||||
std::cout << fmt::format("Output: {}", tensorOutput.data()) << std::endl;
|
||||
}
|
||||
|
||||
|
||||
Logistic Regression Example
|
||||
------------------
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Logistic regression is oftens seen as the hello world in machine learning so we will be using it for our examples.
|
||||
Logistic regression is oftens seen as the hello world in machine learning so we will be using it for our examples. Back to `examples list <#simple-examples>`_.
|
||||
|
||||
.. image:: ../images/logistic-regression.jpg
|
||||
:width: 300px
|
||||
|
||||
|
||||
In summary, we have:
|
||||
|
||||
* Vector `X` with input data (with a pair of inputs `Xi` and `Xj`)
|
||||
* Output `Y` with expected predictions
|
||||
|
||||
* Vector ``X`` with input data (with a pair of inputs ``Xi`` and ``Xj``\ )
|
||||
* Output ``Y`` with expected predictions
|
||||
|
||||
With this we will:
|
||||
|
||||
* Optimize the function simplified as `Y = WX + b`
|
||||
* We'll want our program to learn the parameters `W` and `b`
|
||||
|
||||
* Optimize the function simplified as ``Y = WX + b``
|
||||
* We'll want our program to learn the parameters ``W`` and ``b``
|
||||
|
||||
Converting to Kompute Terminology
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
We will have to convert this into Kompute terminology.
|
||||
|
||||
First specifically around the inputs, we will be using the following:
|
||||
|
||||
* Two vertors for the variable `X`, vector `Xi` and `Xj`
|
||||
* One vector `Y` for the true predictions
|
||||
* A vector `W` containing the two input weight values to use for inference
|
||||
* A vector `B` containing a single input parameter for `b`
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
std::vector<float> wInVec = { 0.001, 0.001 };
|
||||
std::vector<float> bInVec = { 0 };
|
||||
|
||||
std::shared_ptr<kp::Tensor> xI{ new kp::Tensor({ 0, 1, 1, 1, 1 })};
|
||||
std::shared_ptr<kp::Tensor> xJ{ new kp::Tensor({ 0, 0, 0, 1, 1 })};
|
||||
|
||||
std::shared_ptr<kp::Tensor> y{ new kp::Tensor({ 0, 0, 0, 1, 1 })};
|
||||
|
||||
std::shared_ptr<kp::Tensor> wIn{
|
||||
new kp::Tensor(wInVec, kp::Tensor::TensorTypes::eStaging)};
|
||||
|
||||
std::shared_ptr<kp::Tensor> bIn{
|
||||
new kp::Tensor(bInVec, kp::Tensor::TensorTypes::eStaging)};
|
||||
.. code-block::
|
||||
|
||||
|
||||
We will have the following output vectors:
|
||||
We will have to convert this into Kompute terminology.
|
||||
|
||||
* Two output vectors `Wi` and `Wj` to store all the deltas to perform gradient descent on W
|
||||
* One output vector `Bout` to store all the deltas to perform gradient descent on B
|
||||
First specifically around the inputs, we will be using the following:
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
* Two vertors for the variable `X`, vector `Xi` and `Xj`
|
||||
* One vector `Y` for the true predictions
|
||||
* A vector `W` containing the two input weight values to use for inference
|
||||
* A vector `B` containing a single input parameter for `b`
|
||||
|
||||
std::shared_ptr<kp::Tensor> wOutI{ new kp::Tensor({ 0, 0, 0, 0, 0 })};
|
||||
std::shared_ptr<kp::Tensor> wOutJ{ new kp::Tensor({ 0, 0, 0, 0, 0 })};
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
std::shared_ptr<kp::Tensor> bOut{ new kp::Tensor({ 0, 0, 0, 0, 0 })};
|
||||
std::vector<float> wInVec = { 0.001, 0.001 };
|
||||
std::vector<float> bInVec = { 0 };
|
||||
|
||||
std::shared_ptr<kp::Tensor> xI{ new kp::Tensor({ 0, 1, 1, 1, 1 })};
|
||||
std::shared_ptr<kp::Tensor> xJ{ new kp::Tensor({ 0, 0, 0, 1, 1 })};
|
||||
|
||||
std::shared_ptr<kp::Tensor> y{ new kp::Tensor({ 0, 0, 0, 1, 1 })};
|
||||
|
||||
std::shared_ptr<kp::Tensor> wIn{
|
||||
new kp::Tensor(wInVec, kp::Tensor::TensorTypes::eStaging)};
|
||||
|
||||
std::shared_ptr<kp::Tensor> bIn{
|
||||
new kp::Tensor(bInVec, kp::Tensor::TensorTypes::eStaging)};
|
||||
|
||||
|
||||
For simplicity we will store all the tensors inside a params variable:
|
||||
We will have the following output vectors:
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
* Two output vectors `Wi` and `Wj` to store all the deltas to perform gradient descent on W
|
||||
* One output vector `Bout` to store all the deltas to perform gradient descent on B
|
||||
|
||||
std::vector<std::shared_ptr<kp::Tensor>> params =
|
||||
{xI, xJ, y, wIn, wOutI, wOutJ, bIn, bOut};
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
std::shared_ptr<kp::Tensor> wOutI{ new kp::Tensor({ 0, 0, 0, 0, 0 })};
|
||||
std::shared_ptr<kp::Tensor> wOutJ{ new kp::Tensor({ 0, 0, 0, 0, 0 })};
|
||||
|
||||
std::shared_ptr<kp::Tensor> bOut{ new kp::Tensor({ 0, 0, 0, 0, 0 })};
|
||||
|
||||
|
||||
Now that we have the inputs and outputs we will be able to use them in the processing. The workflow we will be using is the following:
|
||||
For simplicity we will store all the tensors inside a params variable:
|
||||
|
||||
1. Create a Sequence to record and submit GPU commands
|
||||
2. Submit OpCreateTensor to create all the tensors
|
||||
3. Record the OpAlgo with the Logistic Regresion shader
|
||||
4. Loop across number of iterations:
|
||||
4-a. Submit algo operation on LR shader
|
||||
4-b. Re-calculate weights from loss
|
||||
5. Print output weights and bias
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
1. Create a sequence to record and submit GPU commands
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
std::vector<std::shared_ptr<kp::Tensor>> params =
|
||||
{xI, xJ, y, wIn, wOutI, wOutJ, bIn, bOut};
|
||||
|
||||
|
||||
Now that we have the inputs and outputs we will be able to use them in the processing. The workflow we will be using is the following:
|
||||
|
||||
1. Create a Sequence to record and submit GPU commands
|
||||
2. Submit OpCreateTensor to create all the tensors
|
||||
3. Record the OpAlgo with the Logistic Regresion shader
|
||||
4. Loop across number of iterations:
|
||||
4-a. Submit algo operation on LR shader
|
||||
4-b. Re-calculate weights from loss
|
||||
5. Print output weights and bias
|
||||
|
||||
1. Create a sequence to record and submit GPU commands
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
|
@ -106,8 +432,10 @@ Now that we have the inputs and outputs we will be able to use them in the proce
|
|||
{
|
||||
// ...
|
||||
|
||||
2. Submit OpCreateTensor to create all the tensors
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
|
||||
#. Submit OpCreateTensor to create all the tensors
|
||||
:raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ ~~
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
|
@ -123,16 +451,19 @@ Now that we have the inputs and outputs we will be able to use them in the proce
|
|||
sq->eval();
|
||||
|
||||
|
||||
3. Record the OpAlgo with the Logistic Regresion shader
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
|
||||
#. Record the OpAlgo with the Logistic Regresion shader
|
||||
:raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ ~~
|
||||
|
||||
Once we re-record, all the instructions that were recorded previosuly are cleared.
|
||||
|
||||
Because of this we can record now the new commands which will consist of the following:
|
||||
|
||||
1. Copy the tensor data from local to device
|
||||
2. Run the logistic regression shader
|
||||
3. Copy the output data
|
||||
|
||||
#. Copy the tensor data from local to device
|
||||
#. Run the logistic regression shader
|
||||
#. Copy the output data
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
|
@ -153,8 +484,10 @@ Because of this we can record now the new commands which will consist of the fol
|
|||
|
||||
sq->end();
|
||||
|
||||
4. Loop across number of iterations + 4-a. Submit algo operation on LR shader
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
|
||||
#. Loop across number of iterations + 4-a. Submit algo operation on LR shader
|
||||
:raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ :raw-html-m2r:`<del>~</del>`\ ~~
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
|
@ -170,39 +503,40 @@ Because of this we can record now the new commands which will consist of the fol
|
|||
sq->eval();
|
||||
|
||||
|
||||
|
||||
4-b. Re-calculate weights from loss
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Once the shader code is executed, we are able to use the outputs from the shader calculation.
|
||||
.. code-block::
|
||||
|
||||
In this case we want to basically add all the calculated weights and bias from the back-prop step.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
Once the shader code is executed, we are able to use the outputs from the shader calculation.
|
||||
|
||||
{
|
||||
// ...
|
||||
for (size_t i = 0; i < ITERATIONS; i++)
|
||||
{
|
||||
// ... continuing from codeblock above
|
||||
In this case we want to basically add all the calculated weights and bias from the back-prop step.
|
||||
|
||||
// Run evaluation which passes data through shader once
|
||||
sq->eval();
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Substract the resulting weights and biases
|
||||
for(size_t j = 0; j < bOut->size(); j++) {
|
||||
wInVec[0] -= wOutI->data()[j];
|
||||
wInVec[1] -= wOutJ->data()[j];
|
||||
bInVec[0] -= bOut->data()[j];
|
||||
}
|
||||
// Set the data for the GPU to use in the next iteration
|
||||
wIn->mapDataIntoHostMemory();
|
||||
bIn->mapDataIntoHostMemory();
|
||||
}
|
||||
{
|
||||
// ...
|
||||
for (size_t i = 0; i < ITERATIONS; i++)
|
||||
{
|
||||
// ... continuing from codeblock above
|
||||
|
||||
5. Print output weights and bias
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
// Run evaluation which passes data through shader once
|
||||
sq->eval();
|
||||
|
||||
// Substract the resulting weights and biases
|
||||
for(size_t j = 0; j < bOut->size(); j++) {
|
||||
wInVec[0] -= wOutI->data()[j];
|
||||
wInVec[1] -= wOutJ->data()[j];
|
||||
bInVec[0] -= bOut->data()[j];
|
||||
}
|
||||
// Set the data for the GPU to use in the next iteration
|
||||
wIn->mapDataIntoHostMemory();
|
||||
bIn->mapDataIntoHostMemory();
|
||||
}
|
||||
|
||||
5. Print output weights and bias
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
|
@ -212,66 +546,63 @@ In this case we want to basically add all the calculated weights and bias from t
|
|||
std::cout << "Bias: " << bIn->data()[0] << std::endl;
|
||||
|
||||
|
||||
|
||||
Logistic Regression Compute Shader
|
||||
------------------------
|
||||
----------------------------------
|
||||
|
||||
Finally you can see the shader used for the logistic regression usecase below:
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
:linenos:
|
||||
|
||||
#version 450
|
||||
#version 450
|
||||
|
||||
layout (constant_id = 0) const uint M = 0;
|
||||
layout (constant_id = 0) const uint M = 0;
|
||||
|
||||
layout (local_size_x = 1) in;
|
||||
layout (local_size_x = 1) in;
|
||||
|
||||
layout(set = 0, binding = 0) buffer bxi { float xi[]; };
|
||||
layout(set = 0, binding = 1) buffer bxj { float xj[]; };
|
||||
layout(set = 0, binding = 2) buffer by { float y[]; };
|
||||
layout(set = 0, binding = 3) buffer bwin { float win[]; };
|
||||
layout(set = 0, binding = 4) buffer bwouti { float wouti[]; };
|
||||
layout(set = 0, binding = 5) buffer bwoutj { float woutj[]; };
|
||||
layout(set = 0, binding = 6) buffer bbin { float bin[]; };
|
||||
layout(set = 0, binding = 7) buffer bbout { float bout[]; };
|
||||
layout(set = 0, binding = 0) buffer bxi { float xi[]; };
|
||||
layout(set = 0, binding = 1) buffer bxj { float xj[]; };
|
||||
layout(set = 0, binding = 2) buffer by { float y[]; };
|
||||
layout(set = 0, binding = 3) buffer bwin { float win[]; };
|
||||
layout(set = 0, binding = 4) buffer bwouti { float wouti[]; };
|
||||
layout(set = 0, binding = 5) buffer bwoutj { float woutj[]; };
|
||||
layout(set = 0, binding = 6) buffer bbin { float bin[]; };
|
||||
layout(set = 0, binding = 7) buffer bbout { float bout[]; };
|
||||
|
||||
float learningRate = 0.1;
|
||||
float m = float(M);
|
||||
float learningRate = 0.1;
|
||||
float m = float(M);
|
||||
|
||||
float sigmoid(float z) {
|
||||
return 1.0 / (1.0 + exp(-z));
|
||||
}
|
||||
float sigmoid(float z) {
|
||||
return 1.0 / (1.0 + exp(-z));
|
||||
}
|
||||
|
||||
float inference(vec2 x, vec2 w, float b) {
|
||||
float z = dot(w, x) + b;
|
||||
float yHat = sigmoid(z);
|
||||
return yHat;
|
||||
}
|
||||
float inference(vec2 x, vec2 w, float b) {
|
||||
float z = dot(w, x) + b;
|
||||
float yHat = sigmoid(z);
|
||||
return yHat;
|
||||
}
|
||||
|
||||
float calculateLoss(float yHat, float y) {
|
||||
return -(y * log(yHat) + (1.0 - y) * log(1.0 - yHat));
|
||||
}
|
||||
float calculateLoss(float yHat, float y) {
|
||||
return -(y * log(yHat) + (1.0 - y) * log(1.0 - yHat));
|
||||
}
|
||||
|
||||
void main() {
|
||||
uint idx = gl_GlobalInvocationID.x;
|
||||
|
||||
vec2 wCurr = vec2(win[0], win[1]);
|
||||
float bCurr = bin[0];
|
||||
|
||||
vec2 xCurr = vec2(xi[idx], xj[idx]);
|
||||
float yCurr = y[idx];
|
||||
|
||||
float yHat = inference(xCurr, wCurr, bCurr);
|
||||
float loss = calculateLoss(yHat, yCurr);
|
||||
|
||||
float dZ = yHat - yCurr;
|
||||
vec2 dW = (1. / m) * xCurr * dZ;
|
||||
float dB = (1. / m) * dZ;
|
||||
wouti[idx] = learningRate * dW.x;
|
||||
woutj[idx] = learningRate * dW.y;
|
||||
bout[idx] = learningRate * dB;
|
||||
}
|
||||
void main() {
|
||||
uint idx = gl_GlobalInvocationID.x;
|
||||
|
||||
vec2 wCurr = vec2(win[0], win[1]);
|
||||
float bCurr = bin[0];
|
||||
|
||||
vec2 xCurr = vec2(xi[idx], xj[idx]);
|
||||
float yCurr = y[idx];
|
||||
|
||||
float yHat = inference(xCurr, wCurr, bCurr);
|
||||
float loss = calculateLoss(yHat, yCurr);
|
||||
|
||||
float dZ = yHat - yCurr;
|
||||
vec2 dW = (1. / m) * xCurr * dZ;
|
||||
float dB = (1. / m) * dZ;
|
||||
wouti[idx] = learningRate * dW.x;
|
||||
woutj[idx] = learningRate * dW.y;
|
||||
bout[idx] = learningRate * dB;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -11,6 +11,10 @@ In this section we will cover the following points:
|
|||
* Asynchronous operation submission
|
||||
* Parallel processing of operations
|
||||
|
||||
|
||||
.. image:: ../images/queue-allocation.jpg
|
||||
:width: 100%
|
||||
|
||||
Asynchronous operation submission
|
||||
---------------------------------
|
||||
|
||||
|
|
@ -22,19 +26,24 @@ It is important that submitting tasks asynchronously, does not mean that these w
|
|||
|
||||
Asynchronous operation submission can be achieved through the kp::Manager, or directly through the kp::Sequence. Below is an example using the Kompute manager.
|
||||
|
||||
Async/Await Example
|
||||
Conceptual Overview
|
||||
^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Asynchronous job submission is done using `evalOpAsync` and `evalOpAwait` functions.
|
||||
|
||||
For simplicity the `evalOpAsyncDefault` and `evalOpAwaitDefault` functions are provided, which can be used similar to the synchronous counterparts (which basically use the default named sequence).
|
||||
|
||||
A simple example of asynchronous submission can be found below.
|
||||
|
||||
One important thing to bare in mind when using asynchronous submissions, is that you should make sure that any overlapping asynchronous functions are run in separate sequences.
|
||||
|
||||
The reason why this is important is that the Await function not only waits for the fence, but also runs the `postEval` functions across all operations, which is required for several operations.
|
||||
|
||||
Async/Await Example
|
||||
^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
A simple example of asynchronous submission can be found below.
|
||||
|
||||
First we are able to create the manager as we normally would.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
|
|
@ -44,9 +53,24 @@ The reason why this is important is that the Await function not only waits for t
|
|||
// Creates tensor an initializes GPU memory (below we show more granularity)
|
||||
auto tensor = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
|
||||
We can now run our first asynchronous command, which in this case we can use the default sequence.
|
||||
|
||||
Sequences can be executed in synchronously or asynchronously without having to change anything.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Create tensors data explicitly in GPU with an operation
|
||||
mgr.evalOpAsyncDefault<kp::OpTensorCreate>({ tensor });
|
||||
|
||||
|
||||
While this is running we can actually do other things like in this case create the shader we'll be using.
|
||||
|
||||
In this case we create a shader that shoudl take a couple of milliseconds to run.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Define your shader as a string (using string literals for simplicity)
|
||||
// (You can also pass the raw compiled bytes, or even path to file)
|
||||
std::string shader(R"(
|
||||
|
|
@ -73,11 +97,28 @@ The reason why this is important is that the Await function not only waits for t
|
|||
}
|
||||
)");
|
||||
|
||||
Now we are able to run the await function on the default sequence.
|
||||
|
||||
If we are using the manager, we need to make sure that we are awaiting the same named sequence that was triggered asynchronously.
|
||||
|
||||
If the sequence is not running or has finished running, it would return immediately.
|
||||
|
||||
The parameter provided is the maximum amount of time to wait in nanoseconds. When the timeout expires, the sequence would return (with false value), but it does not stop the processing in the GPU - the processing would continue as normal.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// We can now await for the previous submitted command
|
||||
// The first parameter can be the amount of time to wait
|
||||
// The time provided is in nanoseconds
|
||||
mgr.evalOpAwaitDefault(10000);
|
||||
|
||||
|
||||
Similar to above we can run other commands such as the `OpAlgoBase` asynchronously.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Run Async Kompute operation on the parameters provided
|
||||
mgr.evalOpAsyncDefault<kp::OpAlgoBase<>>(
|
||||
{ tensor },
|
||||
|
|
@ -89,6 +130,12 @@ The reason why this is important is that the Await function not only waits for t
|
|||
// The default wait time is UINT64_MAX
|
||||
mgr.evalOpAwaitDefault()
|
||||
|
||||
|
||||
Finally, below you can see that we can also run syncrhonous commands without having to change anything.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Sync the GPU memory back to the local tensor
|
||||
// We can still run synchronous jobs in our created sequence
|
||||
mgr.evalOpDefault<kp::OpTensorSyncLocal>({ tensor });
|
||||
|
|
@ -103,6 +150,142 @@ Parallel Operation Submission
|
|||
|
||||
In order to work with parallel execution of tasks, it is important that you understand some of the core GPU processing limitations, as these can be quite broad and hardware dependent, which means they will vary across NVIDIA / AMD / ETC video cards.
|
||||
|
||||
GPUs by default will optimize towards GPU
|
||||
Conceptual Overview
|
||||
^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
If you are familiar with Vulkan, you will have experience that the first few things you do is fetching the physical Queues from the device. The queues themselves tend to have three main particular features - they can be GRAPHICS, TRANSFER and COMPUTE (between a few others we'll skip for simplicity).
|
||||
|
||||
Queues can have multiple properties - namely a queue can be of type GRAPHICS+TRANSFER+COMPUTE, etc. Now here comes the key point: the underlying hardware may (or may not) support parallelized processing at multiple levels.
|
||||
|
||||
Let's take a tangible example. The [NVIDIA 1650](http://vulkan.gpuinfo.org/displayreport.php?id=9700#queuefamilies) for example has 16 `GRAPHICS+TRANSFER+COMPUTE` queues on `familyIndex 0`, then 2 `TRANSFER` queues in `familyIndex 1` and finally 8 `COMPUTE+TRANSFER` queues in `familyIndex 2`.
|
||||
|
||||
With this in mind, the NVIDIA 1650 as of today does not support intra-family parallelization, which means that if you were to submit commands in multiple queues of the same family, these would still be exectured synchronously.
|
||||
|
||||
However the NVIDIA 1650 does support inter-family parallelization, which menas that if we were to submit commands across multiple queues from different families, these would execute in parallel.
|
||||
|
||||
This means that we would be able to execute parallel workloads as long as we're running them across multiple queue families. This is one of the reasons why Vulkan Kompute enables users to explicitly select the underlying queues and queue families to run particular workloads on.
|
||||
|
||||
It is important that you understand what are the capabilities and limitations of your hardware, as parallelization capabilities can vary, so you will want to make sure you account for potential discrepancies in processing structures, mainyl to avoid undesired/unexpected race conditions.
|
||||
|
||||
Parallel Execution Example
|
||||
^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
In this example we will demonstrate how you can set up parallel processing across two compute families to achieve 2x speedups when running processing workloads.
|
||||
|
||||
To start, you will see that we do have to create the manager with extra parameters. This includes the GPU device index we want to use, together with the array of the queues that we want to enable.
|
||||
|
||||
In this case we are using only two queues, which as per the section above, these would be familyIndex 0 which is of type `GRAPHICS+COMPUTE+TRANSFER` and familyIndex 2 which is of type `COMPUTE+TRANSFER`.
|
||||
|
||||
In this case based on the specifications of the NVIDIA 1650 we could define up to 16 graphics queues (familyIndex 0), 2 transfer queues (familyIndex 1), and 8 compute queues (familyIndex 2) in no particular order. This means that we could have something like `{ 0, 1, 1, 2, 2, 2, 0, ... }` as our initialization value.
|
||||
|
||||
You will want to keep track of the indices you initialize your manager, as you will be referring back to this ordering when creating sequences with particular queues.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// In this case we select device 0, and for queues, one queue from familyIndex 0
|
||||
// and one queue from familyIndex 2
|
||||
uint32_t deviceIndex(0);
|
||||
std::vector<uint32_t> familyIndeces = {0, 2};
|
||||
|
||||
// We create a manager with device index, and queues by queue family index
|
||||
kp::Manager mgr(deviceIndex, familyIndeces);
|
||||
|
||||
We are now able to create sequences with a particular queue.
|
||||
|
||||
By default the Kompute Manager is created with device 0, and with a single queue of the first compatible familyIndex. Similarly, by default sequences are created with the first available queue.
|
||||
|
||||
In this case we are able to specify which queue we want to use. Below we initialize "queueOne" named sequence with the graphics family queue, and "queueTwo" with the compute family queue.
|
||||
|
||||
It's worth mentioning you can have multiple sequences referencing the same queue.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// We need to create explicit sequences with their respective queues
|
||||
// The second parameter is the index in the familyIndex array which is relative
|
||||
// to the vector we created the manager with.
|
||||
mgr.createManagedSequence("queueOne", 0);
|
||||
mgr.createManagedSequence("queueTwo", 1);
|
||||
|
||||
We create the tensors without modifications.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Creates tensor an initializes GPU memory (below we show more granularity)
|
||||
auto tensorA = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
auto tensorB = std::make_shared<kp::Tensor>(kp::Tensor(std::vector<float>(10, 0.0)));
|
||||
|
||||
Similar to the asyncrhonous usecase above, we can still run synchronous commands without modifications.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// We run the first step synchronously on the default sequence
|
||||
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorA, tensorB });
|
||||
|
||||
// Define your shader as a string (using string literals for simplicity)
|
||||
// (You can also pass the raw compiled bytes, or even path to file)
|
||||
std::string shader(R"(
|
||||
#version 450
|
||||
|
||||
layout (local_size_x = 1) in;
|
||||
|
||||
layout(set = 0, binding = 0) buffer b { float pb[]; };
|
||||
|
||||
shared uint sharedTotal[1];
|
||||
|
||||
void main() {
|
||||
uint index = gl_GlobalInvocationID.x;
|
||||
|
||||
sharedTotal[0] = 0;
|
||||
|
||||
// Iterating to simulate longer process
|
||||
for (int i = 0; i < 100000000; i++)
|
||||
{
|
||||
atomicAdd(sharedTotal[0], 1);
|
||||
}
|
||||
|
||||
pb[index] = sharedTotal[0];
|
||||
}
|
||||
)");
|
||||
|
||||
Now we can actually trigger the parallel processing, running two OpAlgoBase Operations - each in a different sequence / queue.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Run the first parallel operation in the `queueOne` sequence
|
||||
mgr.evalOpAsync<kp::OpAlgoBase<>>(
|
||||
{ tensorA },
|
||||
"queueOne",
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
// Run the second parallel operation in the `queueTwo` sequence
|
||||
mgr.evalOpAsync<kp::OpAlgoBase<>>(
|
||||
{ tensorB },
|
||||
"queueTwo",
|
||||
std::vector<char>(shader.begin(), shader.end()));
|
||||
|
||||
|
||||
Similar to the asynchronous example above, we are able to do other work whilst the tasks are executing.
|
||||
|
||||
We are able to wait for the tasks to complete by triggering the `evalOpAwait` on the respective sequence.
|
||||
|
||||
.. code-block:: cpp
|
||||
:linenos:
|
||||
|
||||
// Here we can do other work
|
||||
|
||||
// We can now wait for thw two parallel tasks to finish
|
||||
mgr.evalOpAwait("queueOne")
|
||||
mgr.evalOpAwait("queueTwo")
|
||||
|
||||
// Sync the GPU memory back to the local tensor
|
||||
mgr.evalOp<kp::OpTensorSyncLocal>({ tensorA, tensorB });
|
||||
|
||||
// Prints the output: A: 100000000 B: 100000000
|
||||
std::cout << fmt::format("A: {}, B: {}",
|
||||
tensorA.data()[0], tensorB.data()[0]) << std::endl;
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue